I’m really pleased to announce this major update to SQL 4 CDS! This is a complete overhaul of the engine that converts your SQL into something that Dataverse/CRM can understand, and means you can now run a much broader set of queries than ever before.
This is not just a run-of-the-mill update. The basic idea since the very first version of SQL 4 CDS was to convert a SQL statement to a FetchXML query and leave it at that. Version 2 introduced some extra processing where the query couldn’t be fully converted to FetchXML, but there was still the limit of 1 SQL = 1 FetchXML. Version 3 added support for metadata queries and that followed a similar pattern – 1 SQL = 1 Metadata query. You couldn’t mix and match.
This new version brings the level of SQL compatibility to a much higher level and allows you to run queries without the TDS Endpoint that would have previously required it.


Behind the scenes, this update completely replaces the conversion logic with one modelled on SQL Server execution plans. I have to give a large amount of credit here to Hugo Kornelis’s excellent Execution Plan Reference which was my guide for understanding the details of a lot of what SQL Server did for different queries and then trying to translate that to Dataverse.
What’s an execution plan?
An execution plan is the steps that a database engine will run through to get the results of a query. For a simple query like SELECT * FROM table it would just run a scan of the entire table, but as you add filters, sorts, joins etc. it will start building more complex execution plans.
There’s often multiple possible execution plans that would give the same result. A database like SQL Server has a massive amount of information available to help generate the most efficient plan. SQL 4 CDS however doesn’t have much of that available, but it will do the best it can.
You can access an execution plan in SQL 4 CDS by clicking the ![]() button in the toolbar, or select the
button in the toolbar, or select the ![]() button before running a query to have the execution plan displayed as well as the actual results.
button before running a query to have the execution plan displayed as well as the actual results.
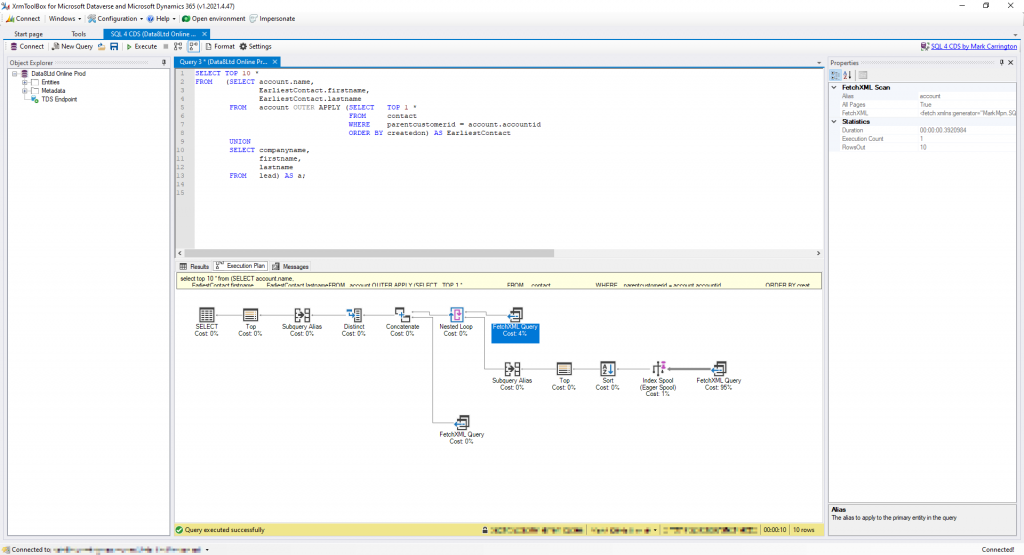
You can read an execution plan as a flow of data from right to left. For example, in this execution plan:

The two FetchXML Query nodes will be executed first and will generate some data which flows to the Concatenate node. This node combines the results and sends it on to the Distinct node. This eliminates any duplicate rows before sending the results to the SELECT node to display it in the grid view. These are the physical operations required to implement the logical UNION operator.
If you get the execution plan as you execute the query you’ll also see the relative cost of each node to help identify ways to make your queries faster.
What does SQL 4 CDS v5 support?
When you run a query in SQL 4 CDS v5, it first builds an execution plan for your query in a similar (but undoubtedly simpler) way to SQL Server. It will still try to move as much of the query processing into the FetchXML or metadata queries as possible, but where the query isn’t supported by FetchXML SQL 4 CDS will now run it itself.
As an example, take a look at this query:
SELECT name FROM account UNION SELECT companyname FROM lead
This generates the execution plan from earlier:
This is a simple example of one SQL query that requires two FetchXML queries to get the required data. SQL 4 CDS then combines the two results to get the final answer.
You’ll also see some interesting results for aggregate queries. Take a look at the seemingly simple query:
SELECT name,
COUNT(*)
FROM account
GROUP BY name
This gives the following execution plan:
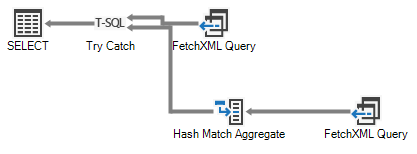
Although FetchXML does support aggregates and could run this query quite happily, it will return an error if there are more than 50,000 records that need to be aggregated. If that happens, the second branch of the try/catch node will be activated. SQL 4 CDS will then retrieve all the required records and process the aggregates itself.
Accessing FetchXML
As well as executing the queries, one way I regularly use SQL 4 CDS is to translate SQL to FetchXML for me to reuse in other tools or scripts. You can still access this conversion by clicking on a FetchXML Query node in the execution plan view and opening the Properties window on the right hand side. Alternatively you can double-click on a FetchXML Query node to open the query straight in FetchXML Builder.
Metadata queries
I’ve simplified the method for querying metadata in this release. There are now 6 “tables” you can query to access metadata information:
metadata.entitymetadata.attributemetadata.relationship_1_nmetadata.relationship_n_1metadata.relationship_n_nmetadata.globaloptionset
All the possible information about different attribute types is now combined into the single attribute table. Only the columns that are applicable to each individual attribute type will be populated. For example, the maxlength column is only populated for string attributes, and will be null for all other types.
You can now combine data and metadata in a single query, e.g.:
SELECT solution.friendlyname,
entity.displayname
FROM solution
INNER JOIN
solutioncomponent
ON solution.solutionid = solutioncomponent.solutionid
INNER JOIN
metadata.entity
ON solutioncomponent.objectid = entity.metadataid
WHERE solutioncomponent.componenttype = 1
ORDER BY 1, 2
This gives you a list of solutions and the names of entities they contain. The execution plan shows it combining the FetchXML and metadata query results:

Paging gotcha workarounds
I’ve previously blogged about various ways paging with FetchXML might not give you the right results, and SQL 4 CDS now makes various changes to its execution plans to avoid these. It can mean more of the query logic is done outside the FetchXML but should give you more reliable results.
DISTINCT without ORDER BY
This was the first problem with paging I highlighted, and affects a query like:
SELECT DISTINCT c.fullname
FROM account
INNER JOIN
contact AS c
ON account.accountid = c.parentcustomerid
Check out the execution plan for this query though, and you’ll see it’s all been converted into FetchXML:
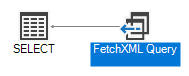
That’s because SQL 4 CDS has added in a sort order to the results to avoid this problem:
<fetch xmlns:generator="MarkMpn.SQL4CDS" distinct="true">
<entity name="account">
<link-entity name="contact" to="accountid" from="parentcustomerid" alias="c" link-type="inner">
<attribute name="fullname" />
<order attribute="fullname" />
</link-entity>
</entity>
</fetch>
Sort on linked entities
Applying a sort order to a joined table makes Dataverse fall back on legacy paging with a 50,000 row limit, so for a query like:
SELECT account.name,
c.fullname
FROM account
INNER JOIN
contact AS c
ON account.accountid = c.parentcustomerid
ORDER BY c.fullname
SQL 4 CDS doesn’t attempt to move this sort order into the FetchXML conversion, but runs the sort process itself:
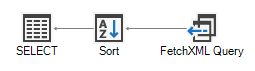
Subqueries
Subqueries can be used in many different ways in your queries. For example, you can use them in the SELECT clause to display data that isn’t immediately available from the tables in the FROM clause:
SELECT name,
(SELECT TOP 1 fullname
FROM contact
WHERE parentcustomerid = account.accountid
ORDER BY createdon) AS EarliestContact
FROM account
This will give you a list of account names and the name of the first contact that was created in each one.
You can also use subqueries with the IN and EXISTS keywords to help filter your data, e.g.:
SELECT name
FROM account
WHERE ownerid IN (SELECT systemuserid
FROM systemuser
WHERE firstname = 'Mark');
SELECT name
FROM account
WHERE EXISTS (SELECT *
FROM contact
WHERE parentcustomerid = account.accountid
AND firstname = 'Mark');
The first query gets the names of accounts that are owned by someone called Mark. The second finds accounts that have at least one contact called Mark.
Subqueries can result in some very different query plans depending on the details of the query, the size of your data and the version of Dataverse/D365 you are running. More recent online versions support at least some IN and EXISTS queries natively in FetchXML, and some queries can be converted into straightforward joins.
For the first type of subquery that adds more data into the SELECT clause, a common execution plan pattern you’ll see is:
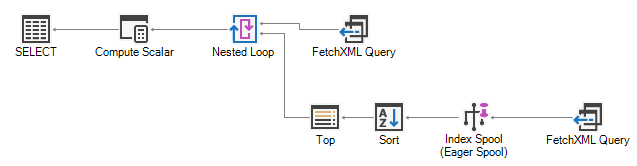
This loads the entire list of contacts into an in-memory index, then searches that index for each account. This works, but isn’t particularly efficient if you have a huge number of contact records. Worse, this process will be repeated for each such subquery, so if you’re seeing this for your queries you might want to investigate other ways of getting the data you require.
APPLY & query-defined tables
SQL 4 CDS now also supports the OUTER APPLY and CROSS APPLY keywords, and the use of query-defined tables in the FROM clause. Taking the example from earlier to get some details of the earliest-created contact for each account we could use OUTER APPLY for this instead:
SELECT account.name,
EarliestContact.firstname,
EarliestContact.lastname
FROM account OUTER APPLY (SELECT TOP 1 *
FROM contact
WHERE parentcustomerid = account.accountid
ORDER BY createdon) AS EarliestContact
This lets you extract multiple columns from the related query without having to run the query multiple times.
Type conversions
SQL 4 CDS supports both implicit and explicit data type conversions. You can run a query to copy data from a text column to a number column and vice versa:
UPDATE account SET new_numberfield = new_textfield
This will trigger an error if the text field contains data that can’t be converted to a number, but so long as the data is valid this query will run as expected.
You can also use CAST and CONVERT to force explicit type conversions. If you want to work with only the date portion of a datetime value:
SELECT CAST (modifiedon AS DATE) FROM account
Feedback
As always I’d love to hear how you’re using SQL 4 CDS, any queries you’re struggling with getting working or other ways you’d like to see it improved. Either add an issue on GitHub or drop me a note on Twitter or LinkedIn and I’ll be happy to take a look! Don’t forget to leave feedback on the XrmToolBox site too!
Hi Mark,
I enjoyed using this tool a lot. Had a quick question on working with Customer type lookup in insert query.
I was able to insert records with normal lookup references by providing the id of the lookup record.
e.g. Account and Parent account (parentaccountid lookup)
Where I am struggling is the lookup of data type ‘Customer’.
I got an error message asking me to include customertype, which I did, but it still does not allow me to insert the record. Any ideas how to get around this error, any help would be much appreciated.
Note: Operator is a Customer type lookup and schema name is prefix_operatorid
If I exclude the ‘prefix_operatorid’ from the query below, the record does get inserted with ‘prefix_operatoridtype’.
Query:
Insert into prefix_applicationoperator (prefix_operatorididtype, prefix_operatorid)
values ( 1, ‘d0d7698f-a9a9-eb11-b1ac-000d3ad8e647’)
Error:
Updating a polymorphic lookup field requires setting the associated type column as well: prefix_operatorid
Add a SET clause for the prefix_operatoridtype column and set it to one of the following values:
* account
* contact
It looks like there’s a couple of errors in the query. You seem to have a repeated “id” in the column name – it should be
prefix_operatoridtyperather thanprefix_operatorididtype. The value you’re inserting for that column should be'account'rather than1.Let me know if you still get an error after making those changes!
Hi Mark,
Thanks for prompt response, much appreciate it. I checked the schema name again, the intellisense shows this schema name in the query and it also inserts if I just select that field and not the ID. This Application Operator is an intersect table where we have Operator(Customer data type) & another lookup link to Application which is a custom entity. When I ran select query on this table I noticed something peculiar, that in prefix_operatorididtype column all the values are NULL, even when I create this intersect record using the form and Select an account record and save it. And there is no other column in this table that shows operator type whether it is Account or Contact. I’ll investigate a bit more and let you know my findings.
Thanks again!
Regards
Ninad
Hi Mark,
thanks for new version, it is great. It simplifies tasks that much, it’s just unbelievable 🙂
I’ve just tried your example:
select cast(modifiedon as DATE) from account
It returns this error:
Der binäre Operator Equal ist für die Typen “System.Data.SqlTypes.SqlDateTime” und “System.Object” nicht definiert.
Can you have a look?
Regards
Olaf
Thanks Olaf, I can reproduce this error. I’ve logged this at https://github.com/MarkMpn/Sql4Cds/issues/80 so you can track progress of fixing this there.
Hi Mark,
I’m sorry but I realized the new version does not perform well when having multiple joins on a query.
The old version put all in one fetch.xml and got a result in short time.
The new version splits up into three fetch.xml ending up in errors like this:
“Der angegebene Schlüssel war nicht im Wörterbuch angegeben.
See the Execution Plan tab for details of where this error occurred”
“Hit maximum retrieval limit. Try limiting the data to retrieve with WHERE clauses or eliminating subqueries
See the Execution Plan tab for details of where this error occurred”
So I have to go back to the old version to get my queries executed.
Is there a way to explicitly trigger the old behaviour using one fetch.xml on the new version?
As the query contains multiple non-standard entities, I will try to analyze deeper and find an example with standard entities so I can provide it to you.
Regards
Olaf
Thanks, I’ve managed to reproduce this with some standard entities now, I’m aiming to get a 5.1 release out this week which will hopefully include a fix for this
Hi before the update I was able to run the query below with no errors but i now get error given key is missing. any help much appreciated:
Error:
The given key was not present in the dictionary.
See the Execution Plan tab for details of where this error occurred
select cga.crimson_activehcontact, cga.crimson_group, count(*) from crimson_contactgroupassignment cga
where cga.statecode = 0 and cga.crimson_activehcontact is not null
group by cga.crimson_activehcontact, cga.crimson_group
having count(*)>1
Thanks for these details, I’ve already got a fix that covers this situation which I’m hoping to release later this week
excellent thank you
Should this not be possible?
select top 10 * from metadata.relationship_1_n;
I get this:
Unable to evaluate query
See the Execution Plan tab for details of where this error occurred
It works fine against metadata.entity or metadata.attribute.
Thanks. Great tool!!!
Thanks Ken, I think this is due to a new property
DenormalizedAttributeNamebeing added in the latest version of the SDK but not yet supported by the server. I’m working on a fix but in the meantime you should be able to run this by replacing*with a list of the columns you actually need, e.g.ReferencedEntityName, ReferencedAttributeNameetc.Hi Mark – enjoy using this tool.
I have come across an error in my SQL which used to work but now I get an error.
“…
Msg 10337, Level 16, State 1, Line 1
The given key was not present in the dictionary.
See the Execution Plan tab for details of where this error occurred
Completion time: 2024-09-05T09:24:06.3862258-04:00
…”
I’m using the latest v9.3.0.0. Could use your insight into what might be wrong with a fairly straightfoward query below –
Thanks.
___________________________________________________
select DISTINCT
(select D.displayname
from metadata.entity as D
where D.logicalname=R.referencingentity) as ThisEntity,
(select D.logicalname
from metadata.entity as D
where D.logicalname=R.referencingentity) as [ThisEntity Logical Name],
R.introducedversion as Version,
E.displayname as DependsOn,
E.logicalname as [DependsOn Logical Name],
E.description as [DependsOn Description]
from metadata.relationship_n_1 as R
left join metadata.entity as E
on E.schemaname=R.referencedentity
where
R.referencingentity=’opportunity’
I’ve moved this to https://github.com/MarkMpn/Sql4Cds/issues/542 to track it for fixing.
I also have the same issue “Msg 10337, Level 16, State 1, Line 1
The given key was not present in the dictionary.” when using a left outer join. works fine with any other join (e.g. right or just join) on the 2 tables but when I change it to a left join I get the message. Am joining to the same table with a different alias
I believe this was fixed in v9.4, if you can still reproduce this error in the latest version can you please post your query as an issue on GitHub?
Hi Mark,
Is it possible to retrieve the metadata of the attribute too? I’m trying to do an audit of all date columns to find the datebehaviour properties (DateOnly, UserLocal etc.) but I can’t find that column in the attribute table
It’s not exposed in the standard
attributetable, but it is in themetadata.attributetable:SELECT logicalname, datetimebehavior FROM metadata.attribute WHERE entitylogicalname = 'account' AND attributetype = 'datetime';