I was reviewing some incredible usage stats for SQL 4 CDS recently which showed that UPDATE statements make up almost 75% of the queries you run! So I thought it was time to add in some improvements in this area that I’ve been meaning to do for a while…
Direct Updates & Deletes
I assume a lot of updates are simple ones targeting a specific record using the primary key, e.g.
UPDATE contact SET firstname = 'Mark' WHERE contactid = '7C4A1C71-62D4-4AA4-BD4A-6D9AE9001031'
or similar deletes like
DELETE contact WHERE contactid = '7C4A1C71-62D4-4AA4-BD4A-6D9AE9001031'
In previous versions this would first run a Fetch XML or SQL query to check that a record existed with that ID before running the update/delete. Assuming you normally write this query because you know this ID exists, this extra read wastes some time as well as an extra API request to count against your usage entitlements or service protection limits. Not a huge amount, but it adds up when you’re running over 250,000 of these requests a day.
This update avoids this initial read by default for these queries, assumes the record exist and issues the UpdateRequest or DeleteRequest. If the record doesn’t exist, SQL 4 CDS handles the error automatically and shows the message (0 Contacts Updated). The only difference you’ll see is if you have your safety limits set to show a warning before updating or deleting more than 0 records, you’ll be prompted if you want to update/delete 1 record first before it finds that the record doesn’t actually exist.
So what difference does this make to the performance? To test, I ran this script to create 10 records and then delete them:
DECLARE @id1 AS UNIQUEIDENTIFIER, @id2 AS UNIQUEIDENTIFIER, @id3 AS UNIQUEIDENTIFIER, @id4 AS UNIQUEIDENTIFIER, @id5 AS UNIQUEIDENTIFIER, @id6 AS UNIQUEIDENTIFIER, @id7 AS UNIQUEIDENTIFIER, @id8 AS UNIQUEIDENTIFIER, @id9 AS UNIQUEIDENTIFIER, @id10 AS UNIQUEIDENTIFIER;
DECLARE @start AS DATETIME, @end AS DATETIME;
DECLARE @msg AS VARCHAR (MAX);
INSERT INTO account (name) VALUES ('test1');
SET @id1 = @@IDENTITY;
INSERT INTO account (name) VALUES ('test2');
SET @id2 = @@IDENTITY;
INSERT INTO account (name) VALUES ('test3');
SET @id3 = @@IDENTITY;
INSERT INTO account (name) VALUES ('test4');
SET @id4 = @@IDENTITY;
INSERT INTO account (name) VALUES ('test5');
SET @id5 = @@IDENTITY;
INSERT INTO account (name) VALUES ('test6');
SET @id6 = @@IDENTITY;
INSERT INTO account (name) VALUES ('test7');
SET @id7 = @@IDENTITY;
INSERT INTO account (name) VALUES ('test8');
SET @id8 = @@IDENTITY;
INSERT INTO account (name) VALUES ('test9');
SET @id9 = @@IDENTITY;
INSERT INTO account (name) VALUES ('test10');
SET @id10 = @@IDENTITY;
SET @start = CURRENT_TIMESTAMP;
DELETE account WHERE accountid = @id1
DELETE account WHERE accountid = @id2
DELETE account WHERE accountid = @id3
DELETE account WHERE accountid = @id4
DELETE account WHERE accountid = @id5
DELETE account WHERE accountid = @id6
DELETE account WHERE accountid = @id7
DELETE account WHERE accountid = @id8
DELETE account WHERE accountid = @id9
DELETE account WHERE accountid = @id10
SET @end = CURRENT_TIMESTAMP;
SET @msg = FORMATMESSAGE('Delete took %s sec', CAST (datediff(ms, @start, @end) / 1000.0 AS VARCHAR (10)));
PRINT @msg;
The original version of this took 5.4 seconds, and the updated version took 4.2 seconds – a speed improvement of 22%!
However, there is a dark side to this – if you try to update/delete a record that doesn’t exist. The old version would spot that by running the initial read and not try to perform the update/delete, and that read is much faster than running an UpdateRequest/DeleteRequest that fails. To test this we can run the same script again, but setting each ID to a random value using the NEWID() function.
This time the original version executes in 0.7 seconds while the new version takes 0.9 seconds.
In general this is a big enough improvement that it is turned on by default, but if you think it is likely for your update/delete statements to reference an ID that doesn’t exist you can revert to the previous behaviour by adding a NO_DIRECT_DML query hint:
UPDATE account
SET ...
WHERE accountid = '<guid>'
OPTION (USE HINT ('NO_DIRECT_DML'))
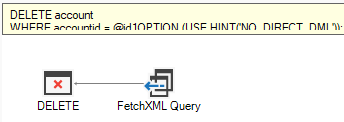
You can always check how your queries are going to be executed using the execution plan. The original version which tries to read the record first will have a FetchXML Query or TDS Endpoint operator at the right hand side:
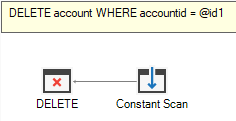
while the new version will have a Constant Scan operator:
Minimal Updates
Another option I’ve wanted to add for a while is the idea of minimal updates. When you update a record in Dataverse, including columns with values they already have is different to not including them at all because it can trigger plugins.
For example, if you have a plugin that runs when the name of a contact changes, if you run:
INSERT INTO contact (firstname, lastname) VALUES ('Mark', 'Carrington');
UPDATE contact
SET firstname = 'Mark'
WHERE contactid = @@IDENTITY
the plugin will run during the UPDATE command, even though it hasn’t really changed.
This might be what you intend, and can be a very useful way of forcing business logic to run. However, if you don’t want that to happen it makes writing bulk UPDATE commands more tricky, especially if you want to be able to update multiple fields. For example:
UPDATE account
SET ownerid = CURRENT_USER,
new_largeaccount = 1
WHERE revenue > 1000000
If you have plugins that run when either of these fields change and you wanted to avoid triggering them a second time when a record already has the desired values you’d need to rewrite this as two queries:
UPDATE account
SET ownerid = CURRENT_USER
WHERE revenue > 1000000
AND ownerid <> CURRENT_USER;
UPDATE account
SET new_largeaccount = 1
WHERE revenue > 1000000
AND (new_largeaccount IS NULL OR new_largeaccount = 0)
To make things easier, this release includes another new query hint that you can apply to the original query instead:
UPDATE account
SET ownerid = CURRENT_USER,
new_largeaccount = 1
WHERE revenue > 1000000
OPTION (USE HINT ('MINIMAL_UPDATES'))
This allows SQL 4 CDS to work out for you, record-by-record, what fields have actually changed. Only those that have changed will be included in the UpdateRequest, and if none have changed at all it will skip the update completely.
For this option to work it has to read the existing record, so the MINIMAL_UPDATES hint implicitly also sets NO_DIRECT_DML.
We can compare the effect of both of these options with a simple example:
DECLARE @start AS DATETIME, @end AS DATETIME, @msg AS NVARCHAR (MAX);
SET @start = GETDATE();
-- Equivalent to previous versions - reads the record and always updates all listed fields
UPDATE contact
SET firstname = 'Sidney',
telephone1 = '555-0104'
WHERE contactid = '342580da-7ccc-e911-a813-000d3a7ed5a2'
OPTION (USE HINT('NO_DIRECT_DML'));
SET @end = GETDATE();
SET @msg = FORMATMESSAGE('Default took %s sec', CAST (datediff(ms, @start, @end) / 1000.0 AS VARCHAR (10)));
PRINT @msg;
SET @start = GETDATE();
-- New default - skips reading the record and tries to update all listed fields
UPDATE contact
SET firstname = 'Sidney',
telephone1 = '555-0104'
WHERE contactid = '342580da-7ccc-e911-a813-000d3a7ed5a2';
SET @end = GETDATE();
SET @msg = FORMATMESSAGE('Direct DML took %s sec', CAST (datediff(ms, @start, @end) / 1000.0 AS VARCHAR (10)));
PRINT @msg;
SET @start = GETDATE();
-- Minimal update - reads the record and only updates any fields that have actually changed
UPDATE contact
SET firstname = 'Sidney',
telephone1 = '555-0104'
WHERE contactid = '342580da-7ccc-e911-a813-000d3a7ed5a2'
OPTION (USE HINT('MINIMAL_UPDATES'));
SET @end = GETDATE();
SET @msg = FORMATMESSAGE('Minimal updates took %s sec', CAST (datediff(ms, @start, @end) / 1000.0 AS VARCHAR (10)));
PRINT @msg;
Here we are updating the same record three times, always with the same values. First we update it in the same way previous versions worked, without the direct updates. Next we try again with the direct updates optimization, and finally we use the minimal updates optimization.
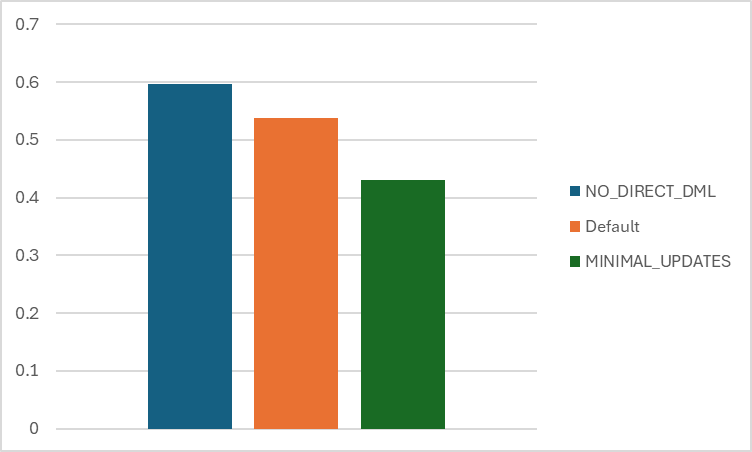
We can see that using the direct update has a performance advantage over the previous version, but in this case because we’re not actually changing anything on this record by the time we get to the MINIMAL_UPDATES version, that is faster again. The performance advantage you see with MINIMAL_UPDATES will vary depending on if SQL 4 CDS can eliminate the update entirely because there are no changes in any of the fields, or if there is a plugin which no longer runs because its trigger field is not updated.
Activity Updates & Deletes
One of the more awkward data types to work with in Dataverse are activities – they share a common activitypointer table which you can read from, but any inserts, updates or deletes need to be written to target the individual table for the specific activity type, e.g. email or phonecall.
In this version you can now delete activities or update them using the activitypointer table directly. For example, you could free up some storage space by deleting old activities:
DELETE activitypointer WHERE createdon > DATEADD(year, -1, GETDATE())
or you could reassign them:
UPDATE activitypointer SET ownerid = CURRENT_USER WHERE regardingobjectid = '<guid>'
Both of these would previously have required you to write multiple copies of the same query, one for each activity type table. Now SQL 4 CDS can automatically determine the type of each activity record it needs to update or delete and construct its request appropriately.
You can also do the same with sharing or unsharing activity records via the principalobjectaccess table.
Other Improvements
NEWID()
SQL 4 CDS now supports the NEWID() method to generate a random guid. The old guidance on avoiding using this when inserting new records still stands – allow Dataverse to generate the ID of a new record for you and use the @@IDENTITY function to get its ID afterwards if you need it. However, this function can be useful if you need to get a random sample of records:
SELECT TOP 10 * FROM account ORDER BY NEWID()
Stored Procedure & Function Parameters
The rules for what Dataverse messages you can call as a stored procedure or table-valued function have been relaxed. You can now invoke a message that return entities without a defined schema, or collections of other .NET types. As an example you can find out what language packs are installed using:
SELECT LocaleId FROM RetrieveAvailableLanguages()
as the LocaleId property on the RetrieveAvailableLanguagesResponse class is now available as a column in the result set.
Date Functions & Conversions
The DATEADD, DATEPART and DATEDIFF functions have all been overhauled to give better compatibility with SQL Server. They now support fractional seconds and respond appropriately to different data types such as datetime, datetime2, datetimeoffset etc. You can now also use the DATETRUNC function as a simpler way to manipulate dates to get the 1st day of the year or month for example:
SELECT DATETRUNC(month, createdon) FROM account
vs
SELECT DATEADD(month, DATEDIFF(month, createdon, 0), 0) FROM account
The conversion from string date to datetime data now also respects your SET DATEFORMAT setting. The default date format is mdy for compatibility with SQL Server and TDS Endpoint, but you can change it if you need more control:
SELECT CONVERT(datetime, '01/02/03'); SET DATEFORMAT dmy; SELECT CONVERT(datetime, '01/02/03');
produces
2003-01-02 00:00:00.000 2003-02-01 00:00:00.000
Hopefully you’re using unambiguous ISO-standard date formats, but if not this might help you avoid some unexpected results!
Hi
I’m using this line in my query
where ls_invoicedate >= CONVERT(datetime, ’01/01/2022′) and ls_invoicedate <= CONVERT(datetime, '12/31/2025')
and then get this error message since I've updated today:
Msg 241, Level 16, State 1, Line 1
Conversion failed when converting date and/or time from character string.
See the Execution Plan tab for details of where this error occurred
Completion time: 2024-11-07T12:09:39.4359634+01:00
in the fetch xml it looks ok
It was working so far but since I’ve updated today this error comes up.
Kind regards
Beat
Thanks, I’m currently tracking this bug at https://github.com/MarkMpn/Sql4Cds/issues/576
How do you get these statistics? Does the SQL 4 Cds library “phone home?”
It uses Application Insights to gather telemetry on usage and errors.