This update focuses mainly on aggregate query performance and introduces .NET Core compatibility for developers wanting to integrate SQL 4 CDS with their own applications.
One type of query I commonly want to run is an aggregate query – this is any query using functions such as COUNT, SUM, MIN, MAX etc, or GROUP BY.
Dynamics 365 has a few restrictions on this though. In particular, if the query aggregates more than 50,000 records it will generate an error.
SQL 4 CDS has had some alternative methods of running these queries for some time already. This update introduces two more optimisations to help run these queries faster on larger data sets.
To find the number of active accounts you can use the query
SELECT count(*) FROM account WHERE statecode = 0;
This generates the following query plan, which has three different attempts to run the query. Each attempt is processed in order from top to bottom until one runs without error.
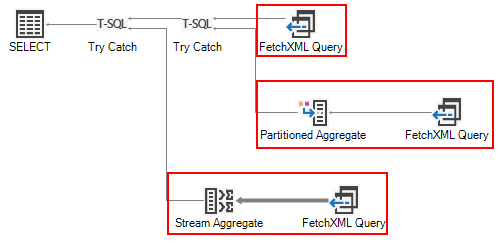
If the aggregate query can be converted to FetchXML, SQL 4 CDS will first try to run it as normal. If it hits the 50,000 limit it will then try a new partitioning strategy.
Partitioned Aggregate
This breaks the data down into half based on the createdon date. The query is then run on each half; if it still hits the 50,000 limit it is halved again until the query runs successfully. The aggregates for each section are then added together to get the final results.
This should work in most cases, but some tables don’t have a createdon field to use for partitioning. It might also fail if the data was loaded over a very short time span so it can’t effectively be split by the createdon field.
Stream Aggregate
If partitioning isn’t possible, SQL 4 CDS will then retrieve all the individual records and calculate the aggregate values itself. This update introduces the Stream Aggregate operator which does this more efficiently than the previous Hash Match Aggregate, and you’ll see this used wherever there are either no GROUP BY fields, or the data can be sorted by those fields.
If for any reason you want to use the Hash Match Aggregate operator you can apply the OPTION (HASH GROUP) query option.
Switching Instances
This update introduces a new drop down list in the toolbar to let you quickly switch to running your query against a different D365 instance.
Click the ![]() icon to add more instances to the Object Explorer pane and they’ll be added to this list too. Select an instance from this list and the current query window will use it the next time you run the query.
icon to add more instances to the Object Explorer pane and they’ll be added to this list too. Select an instance from this list and the current query window will use it the next time you run the query.
FetchXML to SQL Conversion
SQL 4 CDS has long supported converting FetchXML queries to SQL, which you can use from FetchXML Builder.
In this release this is enhanced with the option to use the conversion used behind the scenes by Dynamics 365 itself. This typically gives a more complex SQL query but includes things like the name fields for related lookup values.
On the Settings screen, go to the Conversion tab and select which version you prefer:
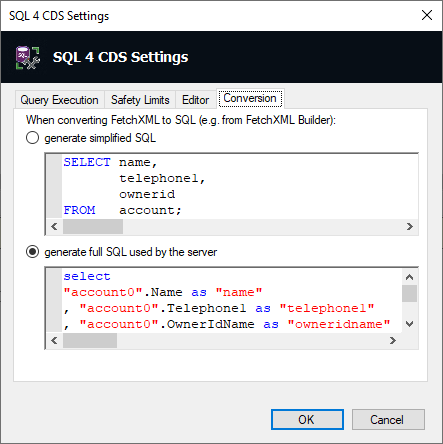
In FetchXML Builder, open the Options page and ensure “Use SQL 4 CDS for SQL conversion” is checked. Now when you click View > SQL you’ll see the query converted using the format you’ve selected. For example, the FetchXML query
<fetch aggregate="true">
<entity name="account">
<attribute name="accountid" alias="count" aggregate="count" />
<filter>
<condition attribute="statecode" operator="eq" value="0" />
</filter>
</entity>
</fetch>
is converted to either the simple SQL query
SELECT count(accountid) AS count FROM account WHERE statecode = 0;
or the more complex
select
COUNT(*) as "count"
, MAX("__AggLimitExceededFlag__") as "__AggregateLimitExceeded__" from (select top 50001 case when ROW_NUMBER() over(order by (SELECT 1)) > 50000 then 1 else 0 end as "__AggLimitExceededFlag__" from Account as "account0"
where
("account0".statecode = 0)) as IQ order by __AggregateLimitExceeded__ DESC
In this second version you can see the 50,000 record limit that is introduced by Dynamics 365.
.NET Core Compatibility
You can now reuse the SQL 4 CDS library in your own .NET Core 3.1 or later applications. This library uses the newer DataverseClient.
The same NuGet package works in .NET Framework as well, but uses the older CrmServiceClient.
There is more information and sample code available to get started with the library on the NuGet page.
Other fixes and improvements
This release also includes a number of fixes for specific queries I’ve seen problems with:
- filtering on partylist fields (e.g. email.to)
- query-derived tables with aggregates
- functions in WHERE clause that can’t be converted to FetchXML
- multi-select picklist fields in ORDER BY and GROUP BY
- LIKE with non-string fields
- more than 10 joins
- using TOP N WITH TIES
- retrieving file columns
- using quoted identifiers
There is also a new option on the Editor tab of the Settings screen to show datetime values in your local format rather than ISO standard format.
Hello Mark
It appears that the SQL 4 CDS 5.4 version is broken when using aggregation.
This query in previous version of SQL 4 CDS was working fine.
SELECT incidentid, knowledgearticleid, COUNT(*)
FROM knowledgearticleincident
–Where StatusCode=1
GROUP BY incidentid, knowledgearticleid
HAVING COUNT(*) > 1
But the 5.4 version returns erroneous results…when I revert to the old version the query works correctly.
The results from 5.4 seem to be not grouping properly by what appears the second group by clause … in my case “knowledgearticleid” … I have an incidentid that has two knowledgearticleid but they are different but counts them as the same
Can you post a screenshot of the execution plan used when you run this query please?
I’d be happy to share but I am not able to copy (Ctrl-C) paste (Ctrl-V) a screenshot into the blog. Could you email me and I’d be happy to provide via that route. Would you want the FetchXML provided by the SQL 4 CDS tool?
Sure, you can send it to sql4cds@markcarrington.dev. Please use the actual execution plan from running the query rather than the estimated one so I can see which branches of the plan were used for your data
Could the “Use TDS Endpoint where possible (Preview)” option in “Settings” have any affect from 5.3 to 5.4? I put 5.4 back and with the above option set the query appears to be returning what I would expect … if I uncheck and rerun I get erroneous results.
Hi Mark,
thank you for introducing the option to show datetime values in local format
Now copying to excel with german locale is working again 🙂
Regards
Olaf
Hi Mark,
you wrote under improvements “more than 10 joins”
I just gave this a try by specifying 12 joins and got this error message:
Number of link entity: 11 exceed limit 10. isReport=False.
See the Execution Plan tab for details of where this error occurred
Do I have to take something else into account?
Regards
Olaf
There shouldn’t be anything special you need to do. Can you post your query please?
The error occurs using a query on non standard entities. When building an example query with standard entities it does not occur so far.
After some investigation I have found the reason. It occours if where clause contains a condition on a virtual field with postfix name
Regards
Olaf
Example:
select top 10 a.name from account a
join contact c1 on c1.accountid = a.accountid
join contact c2 on c2.accountid = a.accountid
join contact c3 on c3.accountid = a.accountid
join contact c4 on c4.accountid = a.accountid
join contact c5 on c5.accountid = a.accountid
join contact c6 on c6.accountid = a.accountid
join contact c7 on c7.accountid = a.accountid
join contact c8 on c8.accountid = a.accountid
join contact c9 on c9.accountid = a.accountid
join contact c10 on c10.accountid = a.accountid
join contact c11 on c11.accountid = a.accountid
where a.primarycontactidname = ‘Test’
Thanks for those details. Adding a filter on a virtual attribute adds a join onto the target entity, so I can see that might bypass the checks on the total number of joins. Could you add an issue to the GitHub repo for this please so I don’t miss it for the next update? https://github.com/MarkMpn/Sql4Cds/issues/new
Hi Mark,
Is any way to avoid the confirmation window when Bypass Custom Plugins is active? I have 1000 individual updates and have to click Yes to every single warning window.
Thanks
Luis
No, at the moment the warning will always be shown when Bypass Custom Plugins is enabled, as this is a potentially dangerous operation. If a way of turning this off would be a useful enhancement, please add an issue to the GitHub repo so I can look at it for the next update – https://github.com/MarkMpn/Sql4Cds/issues/new
Thanks Mark for your reply.
I just came across with your SMS Edition, will download it to play with it.
Hi Mark,
This tool has been extremely helpful to me, thank you! I’m curious if there is a way to replace/remove carriage returns from results? When I copy and paste into Excel it takes a single field of multiple lines of text where line splits exist from character return/line feed and separates those into multiple cells causing the data to live across many rows instead of a single cell. I tried the below replace function but keep getting an error but my statement looks accurate to me. I am using Version 5.4.1.0.
Statement: SELECT replace(replace(description, char(10), ”), char(13), ”)
FROM opportunity
where name = ‘Test only’
Error: Unknown function: char(10)
or: Unknown function: char(13)
Thanks!
Thanks Lindsay!
I haven’t implemented the
CHARfunction yet. You could try using:If you are using an online instance and can enable the TDS Endpoint you could also try enabling the “Use TDS Endpoint where possible” option in the settings page, as that should be able to process the
CHARfunction.Hey Mark, assuming this is just a an Enter / Return keystroke you did after the first single quote, it did not work.
Any other suggestions or intentions to implement the function?
Whether it works will depend on exactly how the line break is encoded in your value, i.e. is it just a carriage return, line feed or both. The value in the string to replace would have to exactly match the values in the database.
I will be including the
CHARfunction and a few others in the next update though.DELETE
https://Test.crm5.dynamics.com/api/data/v9.0/entityName(12478be0-ca0a-ec11-b6e5-000d3a339379)/fileAttributeName
can work.
update entityName set fileAttributeName=null where entityNameId=’02478be0-ca0a-ec11-b6e5-000d3a339379′
can not work.
How to clear the value of attachment type of a record?
At the moment you can’t. There’s much more it could do with file attributes, I’ve created an issue at https://github.com/MarkMpn/Sql4Cds/issues/168 to track it. Thanks for the suggestion!
Hi Mark,
Thanks for creating such an amazing tool! We’ve used this extensively with great success.
However we are currently having an issue. When we try to run delete queries like the one below records are retrieved correctly but the confirm dialog that gives the number of records to delete pops up multiple times (up to 10 times.)
delete top (50000)
from email
where 1 = 1
Records start to be deleted but the query fails quickly stating that the records do not exist. An example is below:
Error deleting Email Messages – ActivityPointer With Id = 3d615bca-6ab7-ec11-983f-00224840e030 Does Not Exist
Error deleting Email Messages – ActivityPointer With Id = 6a999c23-6ab7-ec11-983f-00224840e030 Does Not Exist
See the Execution Plan tab for details of where this error occurred
Similar behaviour deleting other record types.
We’ve tried various setting in terms on the batch and worker thread size, using bulk delete etc. but nothing seems to help. Currently running version 6.0.1.0
Many thanks for any advice,
David
See https://markcarrington.dev/2022/04/11/sql-4-cds-v6-released/#comment-3752
Hi Mark,
this is very great tools to have in hand. may i know is there a way for us to check the row size from a table so we can know the total consumption for each row.
in sql we can achieve using something like this:
declare @table nvarchar(128)
declare @idcol nvarchar(128)
declare @sql nvarchar(max)
–initialize those two values
set @table = ‘YourTable’
set @idcol = ‘some id to recognize the row’
set @sql = ‘select ‘ + @idcol +’ , (0′
select @sql = @sql + ‘ + isnull(datalength(‘ + QUOTENAME(name) + ‘), 1)’
from sys.columns
where object_id = object_id(@table)
and is_computed = 0
set @sql = @sql + ‘) as rowsize from ‘ + @table + ‘ order by rowsize desc’
PRINT @sql
exec (@sql)
regards
henry
At the moment executing dynamic SQL isn’t supported. If it would be useful please add it as an issue to the GitHub site so I can track it for a future update!